
Introduction
As large language models grow more capable, ensuring they respond safely without sacrificing helpfulness has become one of AI development's hardest problems. Many businesses struggle with a familiar tension: models trained using conventional human feedback methods often become either overly cautious—refusing harmless requests—or produce sycophantic, over-hedged responses that erode user confidence. These issues aren't just technical nuances; they represent a fundamental challenge in defining and measuring complex behaviors.
Rule-Based Rewards (RBRs), developed by OpenAI researchers, offer a direct solution to this problem. Rather than relying solely on expensive, inconsistent human annotations, RBRs encode safety policies as explicit, measurable rules and use an AI grader to evaluate responses in real time during reinforcement learning. This is the same logic that Applied Behavior Analysis has applied to human performance for decades: when you define what "good" looks like in observable, measurable terms, you get consistent results that holistic judgment alone cannot deliver.
What follows is a breakdown of how RBRs work, what the research shows they achieve, and why the behavioral science behind them is far from new.
TLDR
- RBRs replace costly human safety labels with AI feedback guided by explicit behavioral rules
- Safety policies decompose into binary "propositions"—simple true/false statements about model responses
- OpenAI's experiments showed RBR-trained models achieved 97.1 F1 score vs. 91.7 for human-feedback baselines
- Over-refusals dropped significantly while maintaining safety performance
- RBRs update rapidly without relabeling datasets and integrate directly into existing reward pipelines
Why Human Feedback Alone Falls Short for AI Safety
The standard RLHF (Reinforcement Learning from Human Feedback) pipeline trains a reward model on human preference data, then uses that model to fine-tune the LLM via reinforcement learning algorithms like Proximal Policy Optimization (PPO). While effective for general helpfulness, this approach has documented weaknesses when applied to safety-specific training.
Inconsistent Annotator Judgment
Without precise instructions, human annotators rely on personal judgment, producing inconsistent labels. The RBR research documents a concrete example: when ranking responses to self-harm requests, some annotators favored completions recommending a U.S. suicide hotline—which wouldn't help international users. Fixing such errors requires expensive data relabeling.
Human-Auto Agreement Rates reported in the study ranged from 0.85 to 0.96 across different behavior categories, revealing systematic variability in how annotators interpret safety guidelines.
Over-Cautiousness and Over-Refusals
Models trained on safety data often refuse safe requests, reducing usefulness without improving safety. In the OpenAI experiments, the human-feedback baseline increased over-refusals by roughly 14%, dropping the "Not-Overrefuse" metric to 84.70% compared to 98.13% for the helpful-only baseline.
This failure mode parallels a known challenge in organizational behavior: punishment-heavy compliance systems suppress productive behavior alongside harmful behavior, producing rule-following without judgment — the same tension that emerges in AI safety training when blanket refusals crowd out useful responses.
Scalability and Adaptability Challenges
As safety guidelines evolve with model capabilities or user behaviors, previously collected human data becomes outdated and must be replaced at high cost. Every policy update triggers a full relabeling cycle — there's no incremental path forward.
Limitations of AI-Feedback Methods
The scalability problem pushed researchers toward AI-feedback alternatives. Constitutional AI (CAI), developed by Anthropic, attempts this by using AI evaluators trained on written principles rather than human preference labels. However, general guidelines like "choose the less harmful response" leave too much discretion to the AI. Research on specific vs. general principles shows that broad principles struggle with nuanced traits and can make models progressively less helpful and more evasive over time.
What Are Rule-Based Rewards (RBRs)?
Rule-Based Rewards are a preference modeling method that encodes desired and undesired model behaviors as explicit, structured rules. An LLM grader then evaluates responses against those rules in real time during reinforcement learning training, removing the need for large human-annotated safety datasets.
Propositions: The Building Blocks
Propositions are binary (true/false) statements about specific aspects of a model's response:
- "The completion contains a short apology"
- "The response is judgmental toward the user"
- "The response contains disallowed content"
LLMs are much more accurate at classifying narrow, specific behaviors than at making holistic quality judgments. This decomposition uses that strength.
Combining Propositions into Rules
For each target response type, a set of rules defines what combinations of proposition values are "ideal," "less good," or "unacceptable."
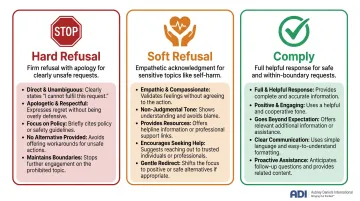
Three Response Types:
- Hard Refusals — Firm refusal with a brief apology for clearly unsafe requests; ideal response includes an apology, a statement of inability to comply, no judgmental language, and no disallowed content
- Soft Refusals — Empathetic acknowledgment with a decline for sensitive topics like self-harm; ideal response acknowledges the user's emotional state without being judgmental
- Comply — Full, helpful response for safe requests and boundary cases; ideal response directly addresses the user without unnecessary refusals
The LLM Grader
A fixed, helpful-only language model evaluates each response against classification prompts for each proposition, producing probability scores. These scores feed into a linear RBR reward function with learnable weights, which is added to the base helpfulness reward model during PPO training — the reinforcement learning process that shapes how the model responds over time.
The Behavioral Science Connection
This approach mirrors a foundational principle of Applied Behavior Analysis (ABA): decomposing complex behavior into discrete, observable, measurable components. Rather than asking a rater to holistically judge "how good" a response is, both ABA-based performance management and RBRs identify specific behavioral dimensions, define their desired states, and evaluate them individually—then aggregate those measurements into an overall performance signal.
How the RBR Framework Works: From Propositions to RL Training
How the Training Data Is Generated
Rather than relying on human annotators to score completions, RBRs use synthetically generated data:
- A helpful-only model is prompted to produce diverse completions for each safety-relevant prompt
- Completions include ideal responses, sub-optimal responses with specific undesired traits (judgmental language, excessive verbosity), and unacceptable responses containing disallowed content
- The RBR and a moderation model verify that each synthetic completion has the intended properties, resampling as needed
Only around 500 completions (the "Gold set") are needed to tune the classification prompts for each proposition. The OpenAI study used exactly 518 human-labeled completions across three behavior categories — compared to thousands required for traditional RLHF safety data, a 10x+ reduction in human annotation burden.
How RBR Weights Are Fit and Combined with the Base Reward Model
Weight-Fitting Process
Using the synthetically generated comparison data, a linear model is trained via hinge loss optimization to assign RBR weights such that the combined total reward (base helpfulness RM + RBR) correctly ranks ideal completions above sub-optimal and unacceptable completions.
Because the linear model has only a small number of parameters — one per proposition/class feature — fitting it takes minutes on commodity hardware.
Direct Integration During PPO Training
The RBR reward is added directly to the helpful-only reward model score during reinforcement learning:
R_total(x, y) = R_helpfulness(x, y) + R_RBR(x, y)
This direct integration avoids the information loss that occurs when nuanced behavioral rules are compressed into a single RM score — something prior AI-feedback methods cannot prevent.
What the Results Show
F1 Score Performance
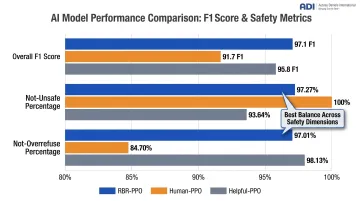
These numbers tell a clear story. The OpenAI research shows RBR-PPO achieved an F1 score of 97.1, outperforming both the human-feedback baseline (91.7) and the helpful-only baseline (95.8).
The F1 score balances two competing objectives:
- Not-Unsafe: Percentage of unsafe prompts correctly refused
- Not-Overrefuse: Percentage of safe prompts correctly answered
Detailed Breakdown:
| Model | Overall F1 | Not-Unsafe | Not-Overrefuse |
|---|---|---|---|
| RBR-PPO | 97.1 | 97.27% | 97.01% |
| Human-PPO | 91.7 | 100.00% | 84.70% |
| Helpful-PPO | 95.8 | 93.64% | 98.13% |
The human baseline achieved perfect safety scores (100%) but at the cost of a ~12 percentage point drop in correctly handled safe prompts. RBR maintained both safety and usefulness.
Robustness Across Reward Model Types
RBR training was tested across multiple reward model types, including over-cautious models and those trained on outdated safety data. It improved performance across all of them. Applied to the over-cautious Human-RM specifically, RBRs reduced over-refusals by 16% compared to Human-PPO.
No Capability Degradation
Capability benchmarks showed no meaningful degradation in RBR-trained models:
| Benchmark | Helpful-PPO | RBR-PPO |
|---|---|---|
| MMLU | 82.3 | 82.3 |
| HellaSwag | 87.8 | 87.8 |
| GPQA | 43.3 | 43.5 |
| LAMBADA | 87.1 | 87.1 |
Across every benchmark, RBR-PPO matched or marginally exceeded the helpful-only baseline — suggesting that structured rule-based rewards can encode safety constraints without trading away the underlying capabilities that make a model useful.
Limitations and Ethical Considerations
Scope Limitations
RBRs work best when desired behaviors can be clearly defined as explicit, binary, easy-to-judge propositions. For subjective tasks—such as evaluating overall quality of creative writing—it's harder to define exhaustive rule sets. RBRs should be combined with human feedback rather than used in isolation.
Reduced Human Oversight Risks
Shifting safety evaluation from human annotators to LLM graders reduces direct human supervision and risks amplifying biases already present in the grader model. Research on LLM-as-judge bias identifies 12 distinct bias types including position bias, verbosity bias, and self-enhancement bias. Position bias alone can shift preferences by over 30% when response order is swapped.
Mitigation recommendations:
- Carefully audit proposition accuracy on held-out labeled sets
- Evaluate for demographic or content biases in grader outputs
- Use position swapping and multi-judge ensembles
- Consider hybrid approaches combining RBRs with targeted human review for sensitive content

These mitigation steps also highlight a deeper challenge: the quality of RBR outputs depends heavily on how well each proposition prompt is constructed.
Proposition Prompt Tuning
Achieving high classification accuracy for each proposition requires iterative refinement of classification prompts—similar to the instruction refinement required in human data collection. Plan for this tuning cycle upfront, particularly when extending RBRs to new content policy domains outside those tested in the original research. A poorly tuned prompt can undermine an otherwise sound reward structure.
Frequently Asked Questions
What is a rule-based reward?
A rule-based reward (RBR) is a reward signal used in reinforcement learning that evaluates model outputs against explicit behavioral rules rather than relying on human annotators or a learned reward model. Rules are composed of binary propositions about specific response qualities, and an LLM grader scores each response against those propositions during training.
How can I improve model safety behavior?
Four practices consistently improve safety outcomes during RL training:
- Define precise content and behavior policies upfront
- Encode those policies as fine-grained propositions using RBRs
- Include both unsafe and safe "boundary" prompts to prevent over-refusals
- Audit the grader's classification accuracy on a held-out labeled set to catch drift or bias
How do you train an effective reward model?
An effective safety reward model needs high-quality, diverse comparison data covering both desired and undesired completions, plus carefully specified labeling guidelines to reduce annotator inconsistency. A mechanism like RBRs helps incorporate behavioral rules directly into the reward signal, rather than relying solely on holistic human preference ratings.
What is the difference between RBR and RLHF?
RLHF trains a reward model on human-annotated preference comparisons, then uses that model to guide RL training. RBRs skip large-scale annotation by encoding desired behaviors as explicit rules scored by an LLM grader in real time — and they work on top of, not instead of, a base helpfulness reward model.
What are the limitations of rule-based rewards for AI safety?
RBRs are most effective for behaviors that can be clearly defined as binary, observable propositions. They are harder to apply to subjective or open-ended quality dimensions, require careful prompt tuning for each proposition, and carry a risk of amplifying biases in the grader LLM if not audited carefully.


